Belediye Yönetiminde Kurumsal Veri Odaklı Yapay Zekâ Asistanı Tasarımı- RAG Tabanlı Bir GPT Mimari Yaklaşımı
10 Şubat 2026 Salı
RAG Tabanlı Bir GPT Mimari Yaklaşımı
Giriş
Yerel yönetimler, günümüzde yalnızca hizmet sunan kurumlar değil; aynı zamanda yoğun veri üreten, veri işleyen ve bu veriler üzerinden karar vermek zorunda olan karmaşık organizasyonlar hâline gelmiştir. Stratejik planlar, faaliyet raporları, bütçe tabloları, meclis kararları, çağrı merkezi kayıtları, saha operasyon verileri, coğrafi bilgi sistemleri (CBS) ve mevzuat metinleri belediyelerin günlük işleyişinde sürekli üretilen veri kaynaklarıdır.
Bu veri hacmi arttıkça temel sorun şu noktada düğümlenir:
“Veri var, ama bilgiye dönüşemiyor.”
Klasik raporlama sistemleri, sabit sorgular ve manuel analiz süreçleri; hız, esneklik ve bağlamsal yorum üretme açısından yetersiz kalmaktadır. Bu bağlamda büyük dil modelleri (LLM – Large Language Models) dikkat çekici bir potansiyel sunsa da, doğrudan kullanıldıklarında kamu kurumları için kritik riskler barındırırlar:
-
Kurumsal veriye doğrudan erişemezler
-
Güncel ve yerel bağlamı kaçırırlar
-
Kaynak göstermezler
-
Güvenlik ve KVKK uyumu zayıftır
Bu çalışma, belediyeler için kurumsal veri odaklı, denetlenebilir, güvenli ve bağlam farkındalığı yüksek bir yapay zekâ asistanının nasıl tasarlanabileceğini; Retrieval-Augmented Generation (RAG) tabanlı bir GPT mimarisi üzerinden ele almaktadır.
Kurumsal Yapay Zekâ Asistanı Nedir, Ne Değildir?
Kurumsal yapay zekâ asistanı, bir organizasyonun kendi veri ekosistemi üzerinde çalışan, karar destek süreçlerini güçlendirmek üzere tasarlanmış, güvenli ve bağlam farkındalığı yüksek bir yazılım katmanıdır. Temel amacı, kurumsal hafızayı doğal dil aracılığıyla erişilebilir kılmak ve yöneticilerin ya da operasyon ekiplerinin ihtiyaç duyduğu bilgiyi doğrulanabilir kaynaklara dayanarak üretmektir. Bu tür sistemler, genel amaçlı üretken yapay zekâ uygulamalarından farklı olarak açık internet verisiyle rastgele çıkarım yapmaz; yalnızca yetkilendirilmiş dokümanlar, operasyonel veri tabanları, analitik sistemler ve kurumsal kayıtlar üzerinden çalışır. Genellikle Retrieval-Augmented Generation (RAG), rol bazlı erişim kontrolü (RBAC), veri maskeleme ve denetim izleri gibi mekanizmalarla desteklenir. Böylece hem veri güvenliği sağlanır hem de üretilen yanıtların kaynağı geriye dönük olarak izlenebilir.
Kurumsal yapay zekâ asistanı bir sohbet botu değildir; çünkü amacı kullanıcıyla serbest diyalog kurmak değil, belirli bir kurumsal bağlam içinde doğru bilgiye hızlı erişim sağlamaktır. Aynı şekilde bir arama motoru da değildir; yalnızca belgeleri listelemek yerine, farklı veri kaynaklarını anlamsal düzeyde ilişkilendirerek yorumlanmış ve karar üretimine uygun hâle getirilmiş çıktılar sunar. Bir diğer önemli nokta, bu sistemlerin tahmine dayalı çalışan bağımsız modeller olmamasıdır. Model, bağlamdan kopuk şekilde “bilgi üretmez”; erişebildiği veri kadar konuşur ve bağlam bulunmadığında yanıt vermemeyi tercih edecek biçimde kurgulanır. Bu yaklaşım, özellikle kamu kurumları gibi hesap verebilirliğin kritik olduğu yapılarda hatalı çıkarım riskini minimize eder.
Özetle kurumsal yapay zekâ asistanı; bilgi arama, analiz ve raporlama süreçlerini tek bir etkileşim katmanında birleştiren, organizasyonun dijital sinir sistemi gibi çalışan bir teknolojidir. Doğru konumlandırıldığında yalnızca operasyonel verimliliği artırmakla kalmaz, aynı zamanda veriyle yönetilen bir kurum kültürünün oluşmasına da zemin hazırlar.
Temel Tasarım İlkeleri
Kurumsal bir yapay zekâ asistanının başarılı olabilmesi yalnızca güçlü bir model kullanımıyla değil, doğru mimari prensipler üzerine inşa edilmesiyle mümkündür. Özellikle belediyeler gibi yüksek veri hacmine sahip, denetlenebilirlik gerektiren ve kamu sorumluluğu taşıyan kurumlarda tasarım ilkeleri; performans kadar güvenlik, şeffaflık ve sürdürülebilirliği de kapsamalıdır. Bu nedenle sistemin temelinde, verinin nasıl kullanılacağı, yanıtların nasıl üretileceği ve yetkinin nasıl yönetileceği gibi konuları net biçimde tanımlayan bir tasarım yaklaşımı bulunmalıdır.
Veri Modele Değil, Model Veriye Gider
Geleneksel yaklaşımda modeller kurumsal verilerle yeniden eğitilmeye çalışılır; ancak bu yöntem hem maliyetli hem de veri güvenliği açısından risklidir. Modern kurumsal mimarilerde tercih edilen yöntem, modelin statik kalması ve ihtiyaç duyduğu bağlamın anlık olarak kurumsal veri katmanından getirilmesidir. Retrieval-Augmented Generation (RAG) yaklaşımı bu prensibi destekler ve modelin yalnızca yetkilendirilmiş içerik üzerinden yanıt üretmesini sağlar. Böylece veri kurum dışına taşınmaz, güncellik korunur ve modelin eski bilgilerle yanlış çıkarım yapma riski önemli ölçüde azalır. Aynı zamanda veri versiyonlama ve denetim süreçleri de daha yönetilebilir hâle gelir.
Kaynak Gösterilebilirlik ve Denetlenebilirlik
Kamu kurumlarında üretilen her bilginin izlenebilir olması kritik bir gerekliliktir. Kurumsal yapay zekâ asistanı, verdiği yanıtların hangi belgeye, hangi veri setine veya hangi tarihli kayda dayandığını açık biçimde gösterebilmelidir. Bu özellik yalnızca teknik bir avantaj değil; kurumsal şeffaflığın ve hesap verebilirliğin de temelidir. Kaynak temelli üretim yaklaşımı, “halüsinasyon” olarak adlandırılan hatalı bilgi üretimini azaltırken denetim mekanizmalarının da sağlıklı çalışmasına olanak tanır.
Rol Bazlı Erişim ve Yetkilendirme (RBAC)
Kurumsal bilgi her kullanıcı için aynı kapsamda sunulmamalıdır. Bir belediye başkanı ile bir birim yöneticisinin erişmesi gereken veri derinliği doğal olarak farklıdır. Bu nedenle yapay zekâ asistanı yalnızca arayüz seviyesinde değil, veri katmanında da rol bazlı erişim kontrolü uygulamalıdır. Kullanıcının yetki profili; hangi veri kaynaklarına erişebileceğini, ne kadar detay görebileceğini ve hangi analizleri talep edebileceğini belirler. Böyle bir yapı hem veri güvenliğini güçlendirir hem de hassas bilgilerin kontrolsüz yayılımını önler.
Güvenlik ve Veri Mahremiyeti
Kurumsal yapay zekâ sistemleri tasarlanırken güvenlik bir özellik değil, mimarinin ayrılmaz bir parçası olarak ele alınmalıdır. Kişisel verilerin maskelenmesi, hassas kayıtların anonimleştirilmesi, tüm sorgu ve yanıtların loglanması ve dış müdahalelere karşı koruma mekanizmalarının kurulması bu yaklaşımın temel bileşenleridir. Özellikle prompt injection gibi model davranışını manipüle etmeye yönelik saldırılara karşı bağlam filtreleme ve politika tabanlı kontrol katmanları uygulanmalıdır. Böylece sistem hem yasal düzenlemelerle uyumlu olur hem de kurumsal riskleri minimize eder.
Bağlam Farkındalığı ve Anlamsal Doğruluk
Kurumsal yapay zekâ asistanının en önemli yetkinliklerinden biri, soruları yalnızca kelime bazında değil anlamsal düzeyde yorumlayabilmesidir. Aynı konu farklı ifadelerle sorulduğunda sistemin doğru veri kümelerine yönelmesi gerekir. Bu da güçlü bir semantik arama altyapısı, doğru parçalara ayrılmış dokümanlar ve kaliteli vektör indeksleme ile mümkündür. Bağlam farkındalığı yüksek bir sistem, parçalı verileri ilişkilendirerek daha bütüncül analizler üretebilir ve yöneticilere gerçek içgörüler sunar.
Yönetici Odaklı Çıktı Tasarımı
Teknik olarak doğru bilgi üretmek tek başına yeterli değildir; bu bilginin karar verici tarafından hızla anlaşılabilir olması gerekir. Bu nedenle kurumsal yapay zekâ asistanı, yanıtlarını ham veri şeklinde değil; yapılandırılmış ve aksiyon üretmeye uygun formatlarda sunmalıdır. Kısa bir yönetici özeti, mevcut durum analizi, potansiyel riskler, fırsatlar ve somut öneriler içeren bir çıktı modeli, yönetsel karar süreçlerini önemli ölçüde hızlandırır. Böylece sistem yalnızca bilgi sağlayan bir araç olmaktan çıkar, stratejik karar destek mekanizmasına dönüşür.
Sürdürülebilirlik ve Ölçeklenebilir Mimari
Belediyelerin veri hacmi ve hizmet alanları sürekli büyür. Bu nedenle tasarlanan yapay zekâ asistanı modüler ve ölçeklenebilir bir mimariye sahip olmalıdır. Yeni veri kaynaklarının sisteme kolayca eklenebilmesi, artan kullanıcı yükünü karşılayabilecek altyapının kurulması ve farklı kurumsal sistemlerle entegrasyonun mümkün olması uzun vadeli başarı için kritik faktörlerdir. Ölçeklenebilir bir yapı, yapay zekâ asistanının pilot bir projeden kurumsal çekirdek sisteme evrilmesini sağlar.
Özetle, kurumsal yapay zekâ asistanının tasarım ilkeleri; teknoloji odaklı olmaktan çok kurum odaklıdır. Doğru kurgulanmış bir mimari, yalnızca bilgiye erişimi hızlandırmaz; aynı zamanda güvenilir, şeffaf ve veriyle yönetilen bir organizasyon yapısının oluşmasına da katkı sağlar.
RAG (Retrieval-Augmented Generation) Yaklaşımı
Retrieval-Augmented Generation (RAG), büyük dil modellerinin (Large Language Models – LLM) kapalı ve statik bilgi sınırlarını aşmak amacıyla geliştirilmiş, bilgi getirme (retrieval) ve doğal dil üretimi (generation) süreçlerini tek bir mimari akışta birleştiren hibrit bir yaklaşımdır. Klasik LLM mimarilerinde model, yalnızca eğitim sürecinde gördüğü veriler üzerinden olasılıksal çıkarımlar yapar; bu durum özellikle kurumsal, güncel ve bağlama özgü bilgi gerektiren senaryolarda ciddi doğruluk ve güvenilirlik sorunlarına yol açar. RAG yaklaşımı, bu sınırlılığı modelin parametrelerini değiştirmeden, harici bilgi kaynaklarını dinamik biçimde yanıt üretim sürecine dahil ederek aşmayı hedefler.
Teknik açıdan RAG mimarisi üç temel bileşenden oluşur: sorgu temsil katmanı, bilgi getirme (retrieval) katmanı ve üretim (generation) katmanı. Süreç, kullanıcının doğal dilde sorduğu bir sorunun vektör uzayında anlamsal bir temsile dönüştürülmesiyle başlar. Bu aşamada genellikle transformer tabanlı embedding modelleri kullanılır. Elde edilen vektör, daha önceden vektörleştirilmiş kurumsal doküman parçalarıyla karşılaştırılır ve anlamsal benzerlik ölçütlerine göre en ilgili içerikler seçilir. Bu içerikler, klasik anahtar kelime aramasından farklı olarak bağlam ve anlam düzeyinde eşleşme sağlar.
Bilgi getirme katmanında kullanılan veri yapıları çoğunlukla vektör veritabanları veya yaklaşık en yakın komşu (ANN – Approximate Nearest Neighbor) algoritmalarını destekleyen indeksleme sistemleridir. Kurumsal belgeler; paragraf, madde veya anlamlı metin blokları hâlinde parçalara ayrılır ve her parça embedding vektörleriyle temsil edilir. Böylece sistem, kullanıcının sorduğu soruyla en yüksek anlamsal yakınlığa sahip içerikleri milisaniyeler içerisinde tespit edebilir. Akademik literatürde bu yaklaşım, bilgi erişim (Information Retrieval) ve doğal dil işleme (NLP) disiplinlerinin birleşim noktası olarak tanımlanmaktadır.
Üretim katmanında ise seçilen bağlam parçaları, büyük dil modeline kontrollü bir “prompt” yapısı içerisinde sunulur. Modelin yanıt üretme alanı, yalnızca bu sağlanan bağlamla sınırlandırılır; böylece modelin bağlam dışı bilgi üretmesi veya varsayımsal çıkarımlar yapması engellenir. Bu mekanizma, literatürde sıkça tartışılan “hallucination” problemini önemli ölçüde azaltır. Model, bilmediği bir konuda tahmin yürütmek yerine, erişebildiği bilgiyle sınırlı kalarak yanıt üretir veya bağlam yetersizse yanıt vermemeyi tercih eder.
Teknolojik açıdan RAG yaklaşımı, kurumsal sistemlerde güvenlik, güncellik ve sürdürülebilirlik avantajları sağlar. Modelin yeniden eğitilmesine gerek kalmadan yeni dokümanlar sisteme eklenebilir; bu da hem operasyonel maliyeti düşürür hem de veri güvenliğini artırır. Özellikle belediyeler gibi sürekli güncellenen mevzuat, rapor ve operasyon verilerine sahip kurumlarda RAG, yaşayan bir bilgi katmanı oluşturulmasına olanak tanır. Ayrıca veri, kurum sınırları içerisinde kalır; model yalnızca yetkilendirilmiş içerikle çalışır.
Akademik perspektiften bakıldığında RAG, “parametrik bilgi” ile “parametrik olmayan bilgi” ayrımını net biçimde ortaya koyar. LLM’in kendi ağırlıkları parametrik bilgiyi temsil ederken, harici dokümanlar parametrik olmayan bilgi olarak değerlendirilir. RAG mimarisi, bu iki bilgi türünü üretim aşamasında birleştirerek hem dilsel akıcılığı hem de bilgi doğruluğunu birlikte optimize etmeyi amaçlar. Son yıllarda yapılan çalışmalar, RAG tabanlı sistemlerin özellikle kapalı alan (domain-specific) uygulamalarda klasik LLM yaklaşımlarına kıyasla daha yüksek doğruluk ve güvenilirlik sağladığını göstermektedir.
Kurumsal yapay zekâ asistanları bağlamında RAG yaklaşımı, yalnızca bir teknik tercih değil; aynı zamanda yönetişimsel bir zorunluluktur. Kaynağı belli olmayan bilgi üretimi, kamu kurumları için kabul edilebilir değildir. RAG sayesinde üretilen her yanıt, belirli dokümanlara ve veri kayıtlarına dayandırılabilir, denetlenebilir ve gerektiğinde geri izlenebilir. Bu özellik, RAG mimarisini belediyeler gibi hesap verebilirlik yükümlülüğü yüksek kurumlar için stratejik bir yapı taşı hâline getirir.
RAG, büyük dil modellerini kurumsal dünyaya uyarlayan en kritik mimari yaklaşımlardan biridir. Modeli “her şeyi bilen” bir yapı olmaktan çıkarıp, kurumsal bilgiye dayalı, kontrollü ve güvenilir bir yorumlayıcı hâline getirir. Bu yönüyle RAG, yapay zekânın kamu yönetiminde sürdürülebilir ve sorumlu biçimde kullanılabilmesinin temel teknolojik dayanaklarından biri olarak değerlendirilebilir. Modelin bilmediği şeyler hakkında konuşmasını engeller.
4.1 RAG Nasıl Çalışır?
-
Kullanıcı doğal dilde bir soru sorar
-
Soru, anlamsal olarak analiz edilir
-
İlgili kurumsal belgeler ve veriler bulunur
-
Bu içerik modele “bağlam” olarak verilir
-
Model, yalnızca bu bağlamdan yola çıkarak yanıt üretir
Model artık “tahmin” etmez, okur ve yorumlar.
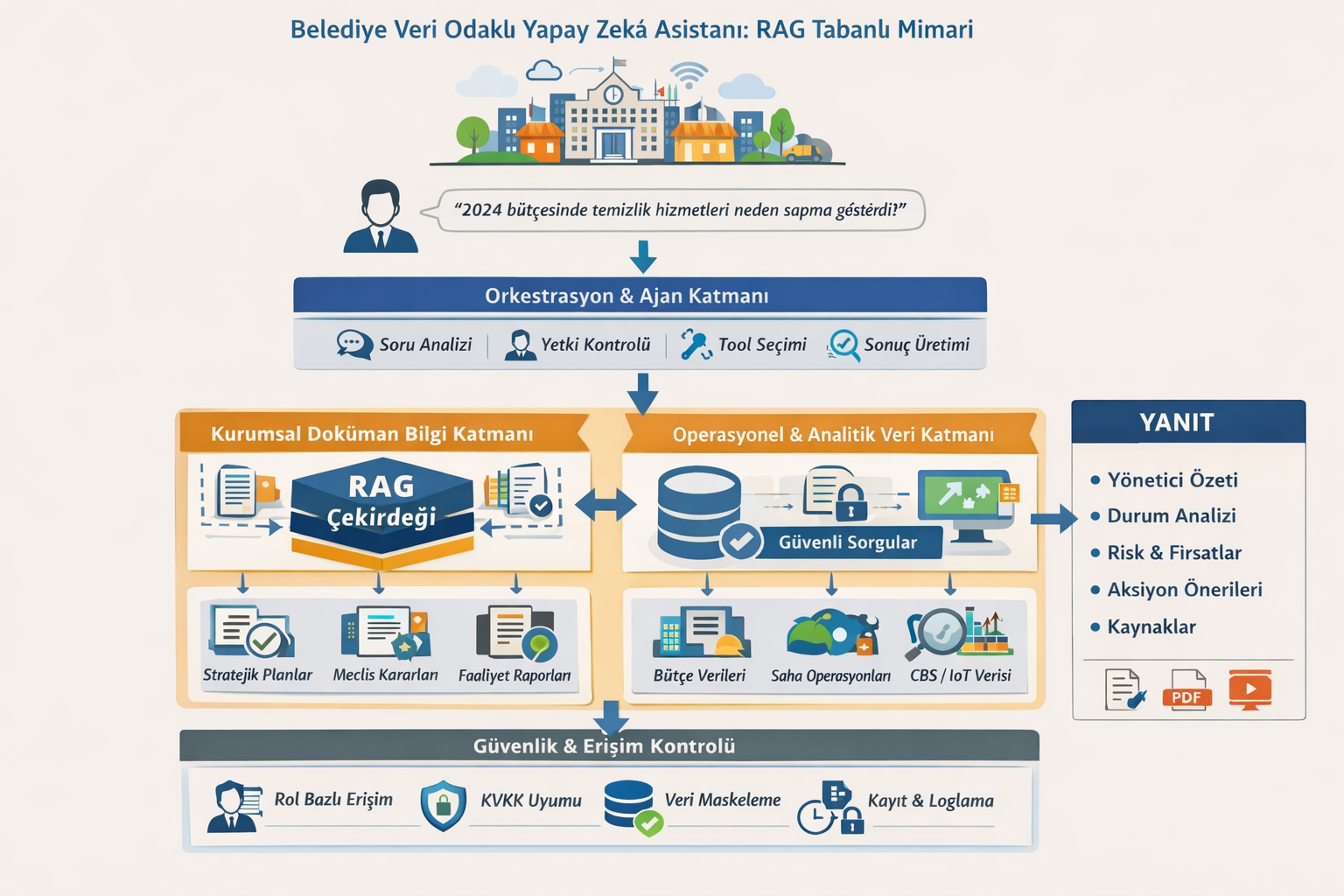
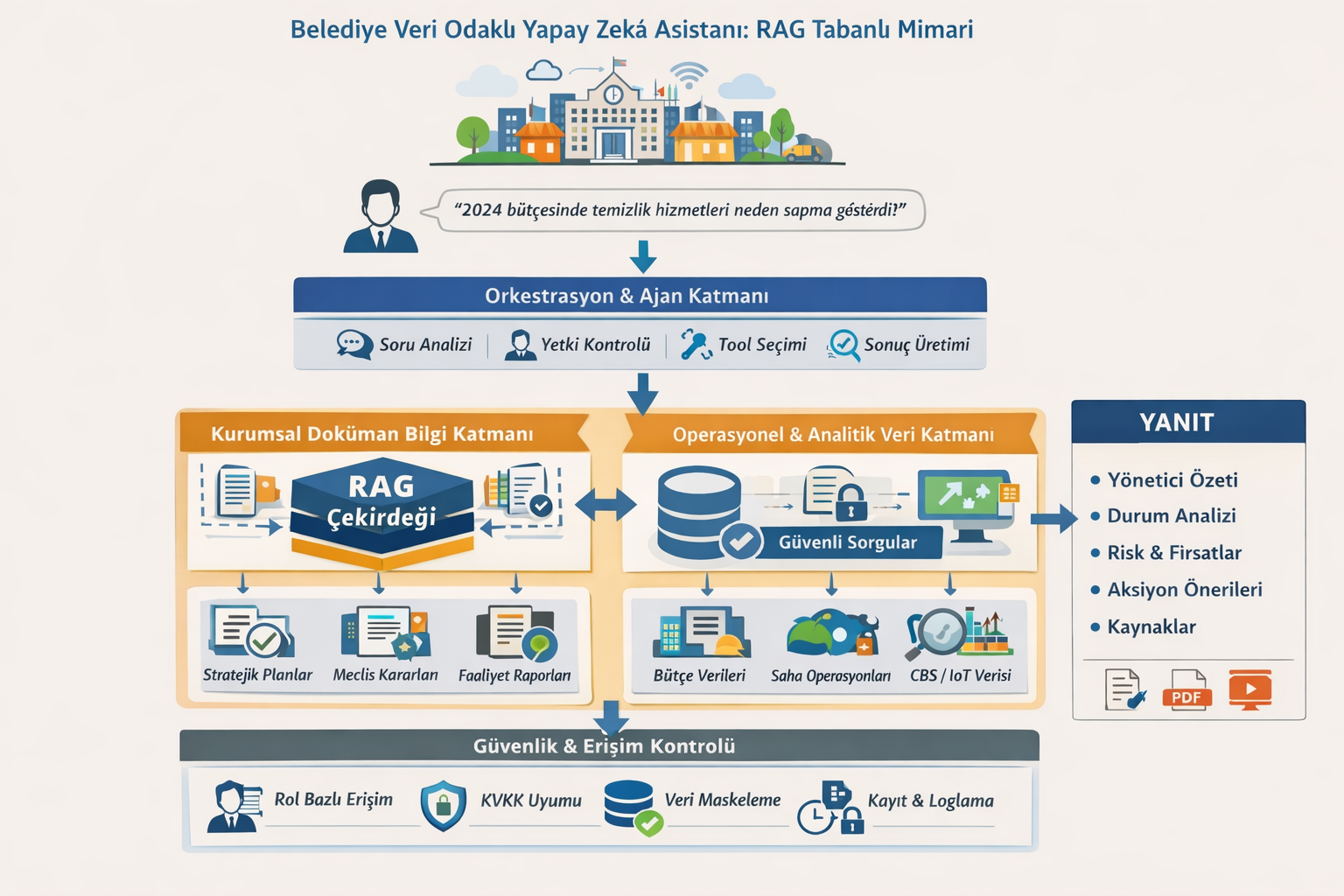
Önerilen Mimari Katmanlar
Kurumsal veri odaklı bir yapay zekâ asistanının sürdürülebilir, güvenli ve yüksek performanslı biçimde çalışabilmesi; katmanlı (layered) bir mimari yaklaşımın benimsenmesini gerektirir. Katmanlı mimari, yazılım mühendisliğinde karmaşıklığı yönetmek, sistem bileşenleri arasında gevşek bağlılık (loose coupling) sağlamak ve ölçeklenebilirliği artırmak amacıyla yaygın olarak kullanılan bir tasarım modelidir. Belediye ölçeğinde kurgulanan bir yapay zekâ platformu ise yalnızca yazılım bileşenlerinden değil; veri altyapısı, ağ topolojisi, güvenlik mekanizmaları ve hesaplama donanımı gibi unsurları da kapsayan bütünleşik bir sistem olarak ele alınmalıdır.
Bu bağlamda önerilen mimari; etkileşim katmanı, orkestrasyon ve ajan katmanı, bilgi getirme (RAG) katmanı, operasyonel veri katmanı, güvenlik ve yönetişim katmanı ile altyapı/donanım katmanından oluşan çok katmanlı bir yapı önerir.
1. Kullanıcı Etkileşim Katmanı (Presentation Layer)
Bu katman, sistem ile son kullanıcı arasındaki temas noktasıdır ve insan-bilgisayar etkileşimi (HCI) prensiplerine uygun biçimde tasarlanmalıdır. Amaç, karmaşık veri ve yapay zekâ süreçlerini kullanıcıdan gizleyerek sezgisel bir deneyim sunmaktır.
Teknolojik açıdan bu katman:
-
Web tabanlı yönetici panelleri
-
Mobil uygulamalar
-
Kurum içi intranet entegrasyonları
-
Kurumsal mesajlaşma platformları
-
Sesli asistan arayüzleri
gibi farklı istemci türlerini destekleyebilir.
Modern mimarilerde bu katman genellikle mikro servis tabanlı backend yapılarıyla iletişim kuran RESTful veya GraphQL API’ler üzerinden çalışır. Ön yüz teknolojileri (ör. React, Angular, Flutter) performans ve modülerlik sağlarken, API geçidi (API Gateway) mimarisi; kimlik doğrulama, oran sınırlama (rate limiting) ve trafik yönetimini merkezi hâle getirir.
Akademik açıdan bu katman, “presentation abstraction” sağlayarak sistem karmaşıklığını soyutlar ve kullanılabilirliği artırır; bu da kurumsal teknolojilerin benimsenmesinde kritik bir faktördür.
2. Orkestrasyon ve Ajan Katmanı (Cognitive Middleware)
Orkestrasyon katmanı, sistemin bilişsel kontrol merkezidir. Kullanıcıdan gelen doğal dil sorguları burada analiz edilir, sınıflandırılır ve uygun veri kaynaklarına yönlendirilir. Bu yapı çoğunlukla LLM tabanlı ajan mimarileri, görev planlayıcılar (task planners) ve karar motorlarıyla desteklenir.
Başlıca işlevleri:
-
Niyet analizi (intent detection)
-
Bağlam yönetimi (context management)
-
Rol bazlı yetkilendirme kontrolü
-
Tool / fonksiyon çağırma mekanizmaları
-
Çok adımlı sorgu yürütme (multi-hop reasoning)
Örneğin tek bir yönetici sorusu; hem bütçe veritabanına sorgu göndermeyi hem de faaliyet raporlarından semantik içerik çekmeyi gerektirebilir. Orkestrasyon katmanı bu süreci otomatikleştirir.
Teknik olarak bu katman:
-
Prompt yönlendirme motorları
-
Ajan framework’leri
-
Mesaj kuyrukları (Kafka, RabbitMQ vb.)
-
Workflow orkestratörleri
ile desteklenebilir.
Yazılım mimarisi perspektifinden bu yapı, domain-driven design (DDD) yaklaşımıyla uyumludur; çünkü iş mantığı burada merkezileştirilir. Akademik literatürde bu tür katmanlar “cognitive architecture” kapsamında değerlendirilir.
3. Kurumsal Doküman ve Bilgi Getirme Katmanı (RAG Core)
Bu katman, sistemin anlamsal hafızasını temsil eder. Kuruma ait yapılandırılmamış veriler burada işlenir ve yapay zekâ tarafından erişilebilir hâle getirilir.
Süreç genellikle şu adımlardan oluşur:
-
Dokümanların normalize edilmesi
-
Anlamsal parçalara bölünmesi (chunking)
-
Embedding üretimi
-
Vektör indeksleme
-
Semantik arama
Bu yapı için çoğunlukla vektör veritabanları ve ANN algoritmaları kullanılır. Hibrit arama (keyword + semantic) yaklaşımları ise erişim doğruluğunu artırır.
Bu katmanda yer alabilecek veri türleri:
-
Stratejik planlar
-
Meclis kararları
-
Yönetmelikler
-
Denetim raporları
-
Proje dokümanları
Akademik açıdan bu yapı, bilgi erişim sistemleri ile üretken modellerin birleşimini temsil eder ve “retrieval-grounded generation” paradigmasına dayanır.
En kritik kazanım:
Model artık tahmin etmez — belgeye dayanarak konuşur.
4. Operasyonel ve Analitik Veri Katmanı (Structured Intelligence Layer)
Kurumsal kararların önemli bölümü yapılandırılmış veriye dayanır. Bu nedenle yapay zekâ asistanı yalnızca dokümanlara değil; canlı sistemlere de kontrollü biçimde erişebilmelidir.
Bu katman genellikle şu sistemleri kapsar:
-
ERP ve bütçe yönetim sistemleri
-
İnsan kaynakları platformları
-
Çağrı merkezi yazılımları
-
CBS ve IoT altyapıları
-
Saha operasyon verileri
Ancak doğrudan veritabanı erişimi yerine şu yöntemler tercih edilmelidir:
-
Güvenli sorgu katmanları
-
Salt okunur veri replikaları
-
API tabanlı erişim
-
Veri ambarı entegrasyonları
Bu yaklaşım hem performansı artırır hem de operasyonel sistemlerin yük altında kalmasını önler.
Teknolojik açıdan veri gölü (data lake) ve veri ambarı (data warehouse) mimarileri, yapay zekâ analizleri için ideal zemin oluşturur.
Güvenlik ve Veri Yönetişimi Katmanı
Kurumsal yapay zekâ sistemlerinde güvenlik sonradan eklenen bir özellik değil; mimarinin çekirdeğidir.
Bu katman şunları kapsar:
-
Rol bazlı erişim kontrolü (RBAC)
-
Çok faktörlü kimlik doğrulama
-
Veri maskeleme ve anonimleştirme
-
Uçtan uca şifreleme
-
Denetim logları
-
Model davranış filtreleri
Ayrıca prompt injection ve veri sızdırma saldırılarına karşı bağlam doğrulama mekanizmaları uygulanmalıdır.
Akademik literatürde bu yaklaşım, AI governance ve trustworthy AI çerçevesinde değerlendirilmektedir.
6. Altyapı ve Donanım Katmanı (Compute Fabric)
Yapay zekâ destekli kurumsal platformlar yüksek hesaplama gücü gerektirir. Bu nedenle altyapı tasarımı, sistem performansını doğrudan belirleyen stratejik bir unsurdur.
Temel bileşenler:
-
GPU veya yüksek çekirdekli CPU kümeleri
-
Konteyner orkestrasyonu (ör. Kubernetes)
-
Yatay ölçeklenebilir bulut mimarileri
-
Yük dengeleyiciler
-
Düşük gecikmeli ağ altyapısı
Hibrit mimariler (on-prem + cloud) özellikle kamu kurumları için ideal bir denge sunar: hassas veri kurum içinde tutulurken, yoğun hesaplama gereksinimleri buluta aktarılabilir.
Akademik açıdan bu yapı, dağıtık sistemler (distributed systems) paradigmasının kurumsal yapay zekâya uygulanmış hâlidir.Önerilen katmanlı mimari, yalnızca teknik bileşenlerin bir araya getirilmesi değildir; aynı zamanda kurumsal bilginin güvenli, ölçeklenebilir ve yorumlanabilir biçimde işlenmesini sağlayan bütüncül bir sistem yaklaşımıdır. Katmanlar arasındaki ayrım, bakım kolaylığı ve sistem evrimi açısından kritik avantajlar sunarken; modüler yapı yeni veri kaynaklarının ve analitik yeteneklerin sisteme kesintisiz biçimde eklenmesine olanak tanır.Bu mimari, yapay zekâyı kurumsal sistemlerin periferisinde çalışan deneysel bir araç olmaktan çıkarıp, organizasyonun dijital çekirdeğine yerleştirir. Böyle bir konumlandırma, belediyelerin veriyle yönetilen, öngörü üretebilen ve stratejik kararları hızlandırabilen kurumlara dönüşmesinde belirleyici bir rol oynayacaktır.
Belediyelerde yapay zekâ, önce güvenliktir.
Uygulanan önlemler:
-
Rol bazlı erişim (RBAC)
-
Kişisel veri maskeleme
-
Sorgu ve yanıt loglama
-
Prompt-injection önleme
-
Kaynaksız cevap üretimini engelleme
Model, bilgi uyduramaz; bağlam yoksa “bilmiyorum” demek zorundadır.
Yanıt Formatı ve Yönetici Değeri
Tipik bir yanıt şu yapıda sunulur:
-
Yönetici Özeti
-
Mevcut Durum Analizi
-
Riskler ve Olası Etkiler
-
Fırsatlar
-
Somut Aksiyon Önerileri
-
Kullanılan Kaynaklar
Gerekirse:
-
PDF
-
Word
-
Sunum çıktısı
üretilir.
Belediyeler İçin Katma Değer
Bu mimari ile belediyeler:
-
Kurumsal hafızayı kişilere bağlı olmaktan çıkarır
-
Karar alma süresini dramatik biçimde kısaltır
-
Stratejik planlama kalitesini artırır
-
Denetim süreçlerini güçlendirir
-
Veriyle konuşan bir yönetim kültürü oluşturur
Bu sistem, dijital dönüşüm değil; yönetsel dönüşüm aracıdır.
Uygulama Yol Haritası
-
RAG tabanlı belge asistanı
-
Yönetici pilot kullanımı
-
Operasyonel sistem entegrasyonları
-
Otomatik raporlama
-
Proaktif uyarı ve senaryo analizi
Sonuç
Belediye yönetiminde yapay zekâ, sohbet etmek için değil; karar vermek için vardır. RAG tabanlı, kurumsal veri odaklı GPT mimarisi; belediyelere güvenli, şeffaf, denetlenebilir ve gerçekten işe yarayan bir yapay zekâ yaklaşımı sunar.
Bu yaklaşım, teknolojik bir lüks değil; veriyle yönetilen kamu kurumları için kaçınılmaz bir adımdır.